배깅(Bagging)과 부스팅(Boosting)의 차이점
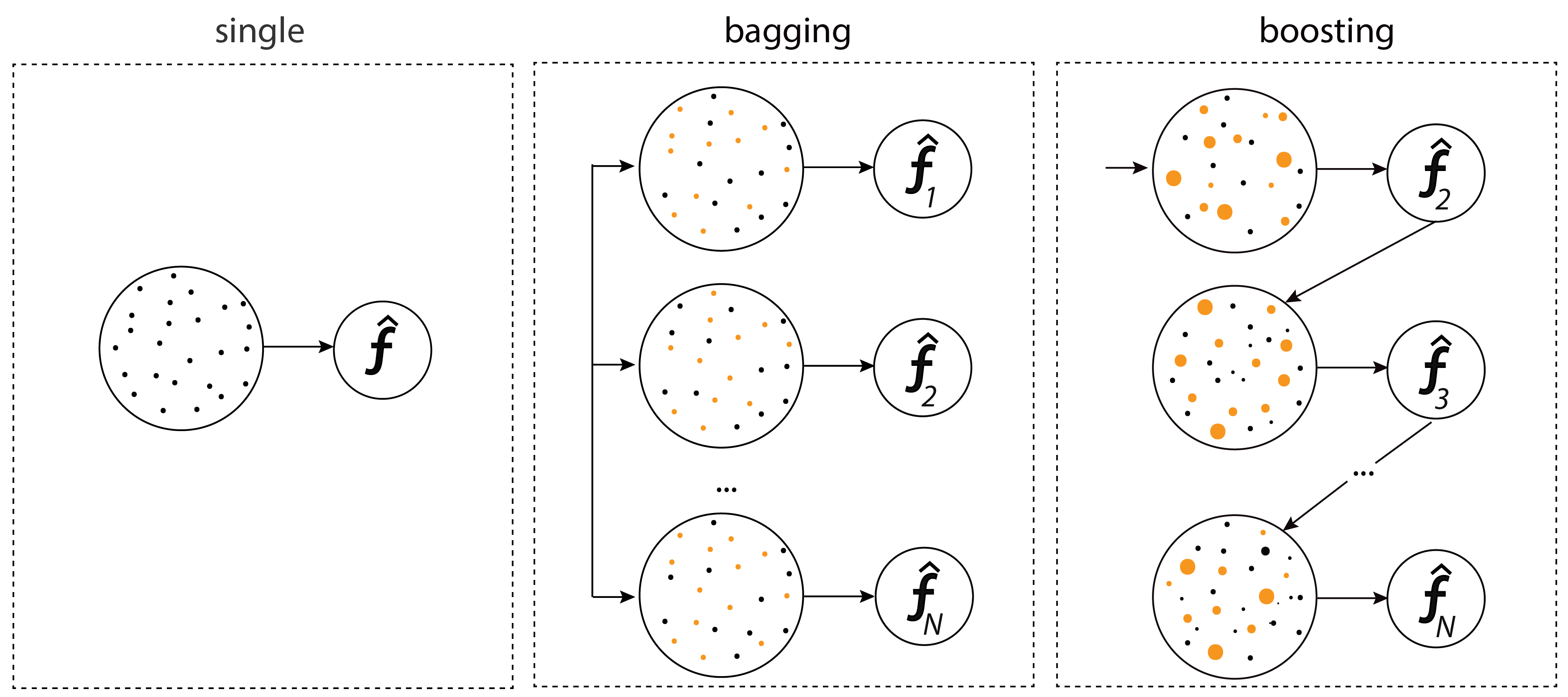
1. m1에 x에서 샘플링된 데이터를 입력
2. y1에서 예측이 잘못된 x중의 값들에 가중치를 반영해서 model m2에 입력
3. y2에서 예측이 잘못된 x' 중의 값들에 가중치를 반영해서 model m3 에 입력
4. 각 모델의 성늘이 다르기 때문에 가중치를 입력
경사 하강법 : Cost 함수(비용함수, 손실함수)의 최소값을 구함

α 는 학습율(Learning rate), 스텝사이즈 (Step-Size) : (얼마나 촘촘히 학습을 할것인가)
대표적인 하이퍼 파라미터
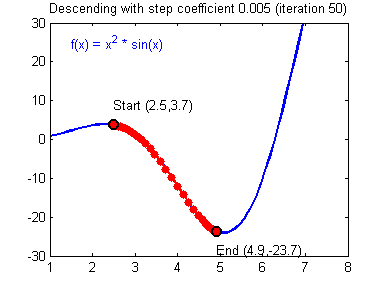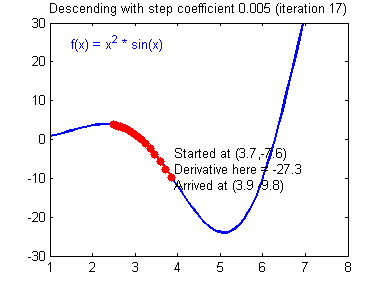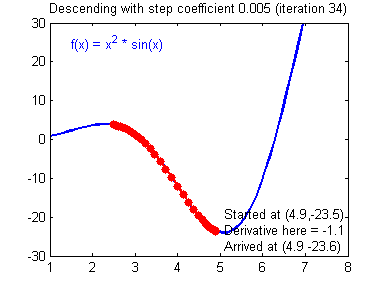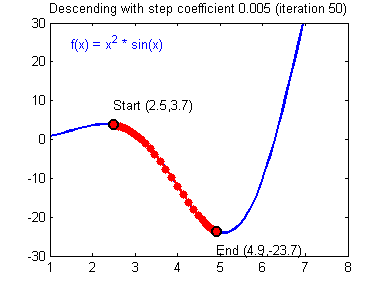
낮은 학습률 :
손실 Loss 감소가 선형의 형태를 보임 천천히 학습됨높은 학습률 :
손실 감소가 지수적인 형태
구간에 따라 빠른 학습 또는 정체가 보임매우 높은 학습률 :
경우에 따라 손실을 오히려 증가시킴올바른 학습률
곡선의 형태
학습률을 조절 하면서 찾아내야함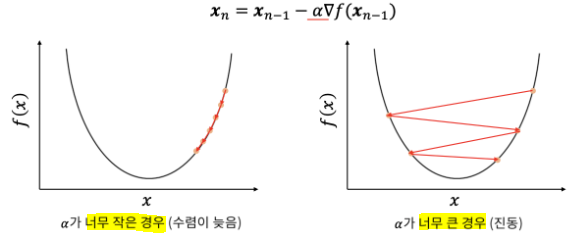
LGBM
리프 기준 분할 (불균형 트리 )
손실값이 가장적은 순으로 빠지는 방식
효율이 좋다
데이터셋이 작으면 과적합( overfitting) 하기 쉬움,
많은 데이터 셋에서는 XGBoost보다 빠른 학습속도, 적은 메모리 사용량
카테고리형 데이터 (범주형 데이터)에 대해서 원 핫 인코딩 필요 없이 인식됨
균형 트리 GBM (level wise) 방식
최대한 균형 잡힌 트리를 유지하며 분할하여 트리의 깊이를 최소화
오버피팅에 강한구조 균형을 위한 시간이 필요
리프중심 트리분할(leaf wise) 방식
최대 손실값을 가지는 리프노드를 지속적으로 분할 하며 트리가 깊어지고 비대칭적 생성
예측 오류 손실을 최소화
'Colab > 머신러닝' 카테고리의 다른 글
| 14. GBoost 02 (0) | 2023.03.10 |
|---|---|
| 13. GBoost 01 (0) | 2023.03.10 |
| 11. 랜덤 포레스트 (random forest) 03 (0) | 2023.03.09 |
| 10. 랜덤 포레스트 (random forest) 02 (0) | 2023.03.09 |
| 09. 랜덤 포레스트 (random forest) 01 (0) | 2023.03.09 |