더보기
if ~ else 를 자동으로 찾아내 예측을 위한 규칙생성
최상위 노드 - root 노드
값이 결정되는 노드 - 리프노드Depth 깊이 - 아래 그림은 3 뎁스
뎁스가 길수록 세분한 분류가 가능하지만 길어지다 보면 과적합이 발생한다지니 불순도
정보이득
엔트로피 개념을 기반
엔트로피 - 무질서한 정도
서로 다른 값이 섞여 있으면 엔트로피가 높음
서로 같은 값이 섞여 있으면 엔트로피가 낮음
정보이득 지수 = 1 - 엔트로피 지수
정보이득 지수는 높을수록 좋다지니계수
지니계수는 낮을수록 좋다
지니계수가 낮을 수록 균일도가 높음
통계적 분산 정도를 정량화해서 표현한 값, 0과 1사이의 값을 가짐
지니계수가 높을 수록 잘 분류되지 못한 것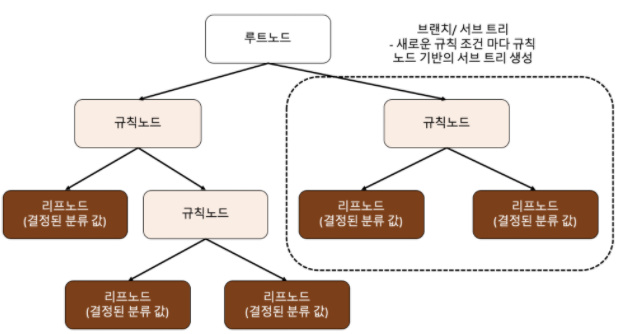
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 1994 미국 성인 소득
# age:근로자 나이, workclass:고용형태, education:교육수준
# hours-per-week:주당 근로시간, occupation:직업
df = pd.read_csv('/content/drive/MyDrive/sample/adult.csv')
print(df['income'].value_counts(normalize=True))
df['income'] = np.where(df['income']=='>50K', 'high', 'low')
df['income'].value_counts(normalize=True)
df = df.drop(columns='fnlwgt')더보기
<=50K 0.760718
>50K 0.239282
Name: income, dtype: float64
>50K 0.239282
Name: income, dtype: float64
df_tmp = df[['sex']]
df_tmp['sex'].value_counts(normalize=True)
df_tmp = pd.get_dummies(df_tmp)
target = df['income']
target
df = df.drop(columns='income')
df = pd.get_dummies(df)
df['income'] = target
dffrom sklearn.model_selection import train_test_split
from sklearn import tree
X_train, X_test = \
train_test_split(df, test_size=0.3,
stratify=df['income'],
random_state=123)
model = tree.DecisionTreeClassifier(random_state=123,
max_depth=3)
y_train = X_train['income']
X_train = X_train.drop(columns='income')
model.fit(X=X_train, y=y_train)
plt.rcParams.update({'figure.dpi':'100',
'figure.figsize':[12,8]})
tree.plot_tree(model)
tree.plot_tree(model,
feature_names=X_train.columns, # 예측변수명
class_names=['high', 'low'], # target
proportion=True, # 비율
filled=True, # 색칠
rounded=True, # 둥근 테두리
impurity=True, # 불순도
label='root', # label 표시위치
fontsize=10) # 폰트 크기
y_test = X_test['income']
X_test = X_test.drop(columns='income')
X_test['pred'] = model.predict(X_test)더보기
11175 low
2808 low
556 high
10435 low
24194 low
...
25151 low
37562 high
670 low
32582 high
34217 high
Name: pred, Length: 14653, dtype: object
from sklearn.metrics import confusion_matrix,accuracy_score, precision_score,recall_score, f1_score
from sklearn.metrics import ConfusionMatrixDisplay
conf_mat = confusion_matrix(y_true=y_test,
y_pred=X_test['pred'],
labels=['high', 'low'])
p = ConfusionMatrixDisplay(confusion_matrix=conf_mat,
display_labels=('high', 'low'))
p.plot(cmap='Blues')
print(accuracy_score(y_true=y_test,
y_pred=X_test['pred']))
print(recall_score(y_true=y_test,
y_pred=X_test['pred'],
pos_label='high'))
print(precision_score(y_true=y_test,
y_pred=X_test['pred'],
pos_label='high'))
print(f1_score(y_true=y_test,
y_pred=X_test['pred'],
pos_label='high'))더보기
0.8431038012693647
0.5139760410724472
0.75177304964539
0.6105370150770795
'Colab > 머신러닝' 카테고리의 다른 글
| 09. 랜덤 포레스트 (random forest) 01 (0) | 2023.03.09 |
|---|---|
| 08. 결정 트리 (Decision Tree) 02 (0) | 2023.03.08 |
| 06. K-최근접 이웃 회귀 K-NN Regression (0) | 2023.03.06 |
| 05. 로지스틱 회귀분석 Logistic Regression (0) | 2023.03.03 |
| 04. 선형회귀(linear regression) - 학습, 테스트 (0) | 2023.03.02 |